Übersicht
1 Grundlagen
In ComfyUI und allgemein bei der Arbeit mit KI-Modellen besteht stets die Herausforderung, dem Modell zu vermitteln, was wir möchten. Dafür nutzen wir verschiedene Werkzeuge wie Textprompts, ControlNets oder Loras, um Stil oder Inhalt zu beeinflussen.
Unter diesen Methoden sind Masken eines der mächtigsten Werkzeuge: Wer es schafft, Masken präzise und möglichst unkompliziert zu erstellen, verfügt über eine wertvolle Fähigkeit.
In diesem Artikel erkläre ich Schritt für Schritt meinen Masking-Workflow in ComfyUI und die Grundlagen von Masking – inklusive kostenlosem Download.
Der Workflow umfasst:
- BiRefNet: Präzise Maskierung
- Florence 2: Automatische Maskierung mit Prompts
Dabei erkläre ich detailliert die Parameter der Nodes, die du für die Maskenerstellung benötigst – damit du schnelle, exakte und professionelle Ergebnisse erzielst.
Grundsätzlich dient eine Maske dazu, die darunterliegende Ebene gezielt sichtbar oder unsichtbar zu machen.
- Weiß: Ebene sichtbar
- Schwarz: Ebene unsichtbar
- Grau: Ebene teilweise transparent
Als Merkhilfe gilt der Satz:
„Black hides, white reveals“ oder „Schwarz verdeckt, Weiß zeigt“.
Das Nützliche an Masken – und der Grund, warum sie in der herkömmlichen als auch in der KI-gestützten Bildgenerierung so wichtig sind – besteht darin, dass man mit ihnen klare Grenzen setzen und gezielt festlegen kann, was geändert werden soll und was nicht. Außerdem kann man mit Masken zerstörungsfrei arbeiten, da sie keine Pixel löschen. Alle Änderungen bleiben flexibel, und das ursprüngliche Bild bleibt erhalten.
Masken händisch exakt anzupassen kann zermürbende Arbeit sein, da komplexe oder detaillierte Bereiche oft sehr aufwendig zu bearbeiten sind. Das gilt besonders für das Arbeiten mit dem Mask Editor in ComfyUI. Feine Details und weiche Übergänge erfordern viel Geduld oder sind sogar unmöglich in ComfyUI händisch zu maskieren.
Um Masking effizient einzusetzen und einen reibungslosen Workflow in ComfyUI zu gewährleisten, ist es hilfreich, grundlegende technische Zusammenhänge zu verstehen. Besonders wichtig ist hierbei das Verständnis der Bilddimensionen.
Bilddimensionen
Ein PNG-Bild hat normalerweise drei Farbkanäle: Rot, Grün und Blau (RGB). Jeder dieser Kanäle enthält Informationen darüber, wie intensiv die jeweilige Farbe an jedem Pixel dargestellt wird. Ein Bild im RGB-Format ist daher dreidimensional, weil es für jeden Pixel drei Werte (R, G, B) speichert.
Legt man zusätzlich eine Maske auf ein RGB-Bild, kommt ein vierter Kanal hinzu: der sogenannte Alpha-Kanal. Dieser Kanal bestimmt die Transparenz jedes Pixels. Durch den Alpha-Kanal hat das Bild insgesamt vier Farbkanäle, weshalb man von einem „RGBA-Bild“ spricht.
Beim Arbeiten in ComfyUI spielen die Bilddimensionen eine wichtige Rolle. Manche Nodes erwarten eine feste Anzahl an Farbkanälen, wodurch Unterschiede in der Dimension zu Fehlern führen können oder der Alpha-Kanal geht verloren.
Beispiel:
- Die PreviewBridge in ComfyUI gibt den Alpha-Kanal im Image-Output nicht weiter. Dadurch wird ein RGBA-Bild automatisch zu einem RGB-Bild, und die Transparenz geht verloren.
Da Bilddimensionen in ComfyUI eine wichtige Rolle spielen, sollte man sie immer im Blick behalten, um unerwartetes Verhalten zu vermeiden. Im Masking-Workflow gibt es die Image Info Group, damit du die Dimensionen(Channel) und andere Bildeigenschaften immer im Blick hast.
2 BiRefNet
BiRefNet ist in ComfyUI eines der präzisesten Modelle zur automatischen Maskenerstellung. Es ist gut darin die feinen Details bei hochauflösenden Bildern zu erfassen die viele andere Modelle übersehen.
Das aktuellste Modell, BiRefNet_HR-Matting, wurde am 12. Februar 2025 veröffentlicht und an 2048×2048 Pixel großen Bildern trainiert. HR steht für High Resolution. Allerdings ist das Modell auf Hugging Face ausschließlich als .safetensors-Datei zum Download verfügbar. Die BiRefNetUltraV2-Node, mit der ich es nutze, unterstützt jedoch nur .pth-Dateien.
Die .pth-Dateien von BiRefNet_HR-Matting und BiRefNet_HR könnt ihr weiter unten im Artikel Herunterladen.
Im Gegensatz zu Florence-2, welches textbasierte Prompts zur Steuerung der Maskenerstellung nutzt, arbeitet BiRefNet ohne solche Prompts. Deshalb ist es ratsam, dass das gewünschte Objekt bereits im Mittelpunkt des Bildes ist.
Auch wenn die BiRefNet-Modelle wirklich gut sind, hängt die Qualität und Geschwindigkeit der Maskenanpassung in ComfyUI entscheidend davon ab, wie gut du die BiRefNet Ultra V2 Node beherrschst.
Die Maskenerstellung erfolgt dabei in zwei Schritten:
- Erstellung der Grundmaske mit dem BiRefNet-Modell
- Maskenoptimierung mit Detailmethoden wie VITMatte
Wenn du mit meinem Masking-Workflow arbeitest, sind die Erklärungen direkt an der Node verfügbar, sodass du schnell nachschauen kannst.
BiRefNet-Modelle
BiRefNet_HR-matting.pth:
Oder über die Huggingfaceseite:
- Datei: model.safetensors
- Link: https://huggingface.co/ZhengPeng7/BiRefNet_HR-matting/tree/main Wichtig: Die .safetensors-Datei muss in .pth umgewandelt werden, um in der Node verwendbar zu sein!
BiRefNet_HR.pth:
Oder über die Huggingfaceseite:
- Datei: model.safetensor
- Link: https://huggingface.co/ZhengPeng7/BiRefNet_HR/tree/main Wichtig: Die .safetensors-Datei muss in .pth umgewandelt werden, um in der Node verwendbar zu sein!
VitMatte Modelle
Übernehmen die Aufgabe, komplexe Details wie feine Kanten, Haare oder transparente Bereiche präziser herauszuarbeiten.
vitmatte-base-composition-1k
- Dateien: config.json, preprocessor_config.json, pytorch_model.bin
vitmatte-small-composition-1k
- Dateien: config.json, preprocessor_config.json, pytorch_model.bin
- Link: https://huggingface.co/hustvl/vitmatte-small-composition
Modell-Setup: BiRefNet und VITMatte
Um die Modelle mit den Nodes Load BiRefNet Model und BiRefNetUltraV2 in ComfyUI nutzen zu können, müssen die Modelldateien richtig abgelegt werden.
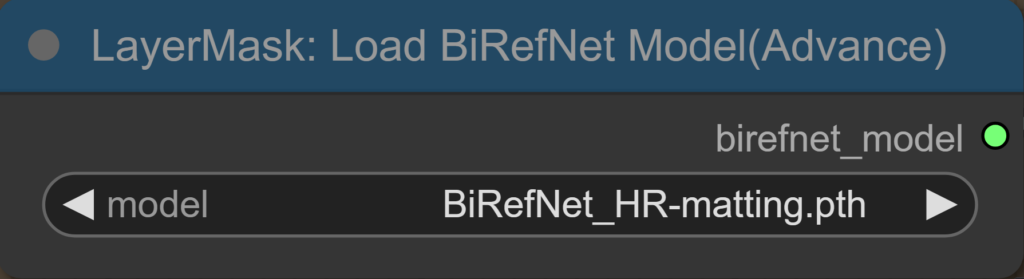
1. BiRefNet Modell einrichten
- Im Verzeichnis
modelseinen Ordnerbirefnetanlegen. - Im Ordner
birefneteinen Unterordnerptherstellen. - Die
.pth-Modelldatei in denpthOrdner legen.
2. VITMatte Modell einrichten
- Im Verzeichnis
modelseinen Ordnervitmatteanlegen. - Folgende Dateien in den Ordner
vitmattemodel.pthconfig.yamlpreprocessor_config.yaml
Hinweis: Immer nur ein Modell im VITMatte-Ordner belassen, damit nur dieses genutzt wird.
BiRefNet Ultra V2
Gute Masken in ComfyUI entstehen durch das richtige Verständnis der Detailparameter. Neben der Wahl des passenden Modells sind die richtigen Einstellungen entscheidend für die Maskenqualität. Es lohnt sich, den Masking-Workflow zu nutzen, um ein Gefühl für die Parameter zu bekommen.
Im nächsten Teil erkläre ich die einzelnen Parameter und zeige dir anhand von Beispielbildern, wie sie sich auf die Maskenqualität auswirken.
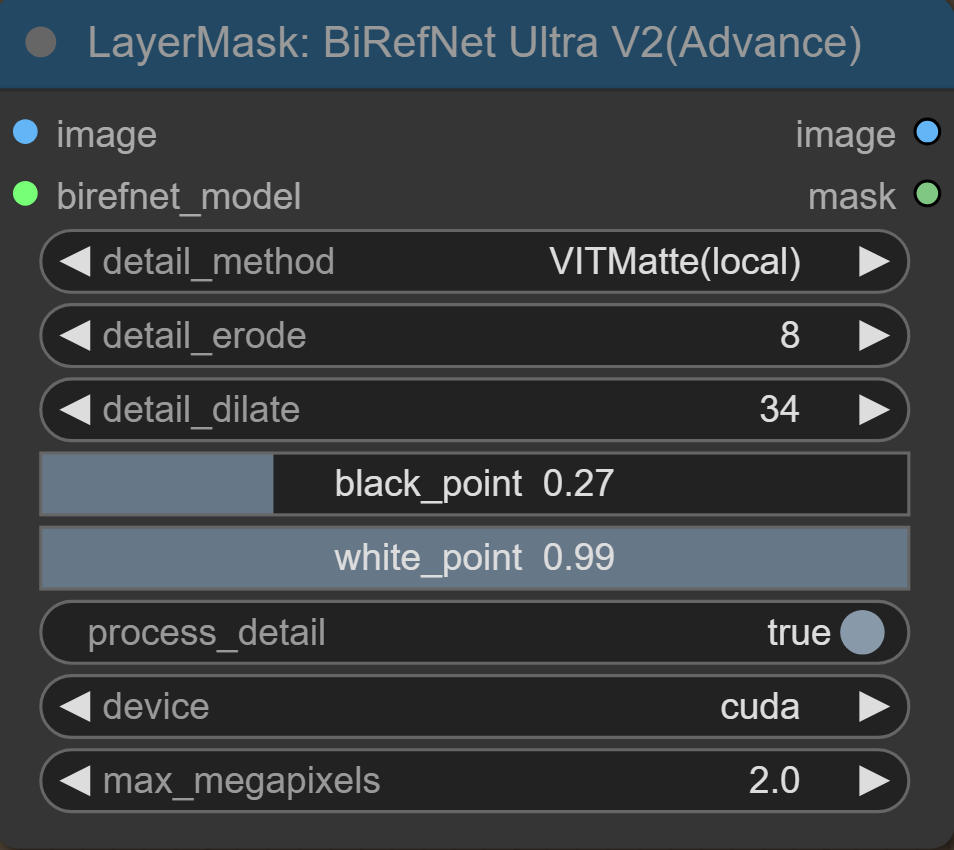
Detail_Method
Beim Bildmatting geht es um die präzise Trennung des Vordergrunds vom Hintergrund.



Die Detailmethoden bei der BiRefNet-Node sind wichtig für die Verbesserung der Kantenqualität. Für die besten Ergebnisse empfehle ich das Base VITMatte Modell, mit dem ich auch das Beispielbild erstellt habe. Allerdings hängt die Wahl letztlich vom Anwendungsfall ab.
- VITMatte: Diese Methode liefert die beste Kantenqualität mit scharfen und klaren Details.
- PYMatting: Die schwächste Methode, da feine Details oft durch Treppeneffekte verzerrt werden.
- Guided Filter: Erzeugt weichere Kanten, was harmonischer wirkt, aber auf Kosten der Detailgenauigkeit geht.
Je nach Bild und gewünschtem Ergebnis lohnt es sich, die Methoden auszuprobieren, um die optimale Qualität zu erzielen.
Detail_Erode


Bei Detail Erode geht es darum, wie nah ein Grauwert an Schwarz ist. Je näher ein Grauwert an Schwarz liegt, desto eher wird er „weggeschliffen“ und in Schwarz umgewandelt. Das bedeutet, die Maske wird von den weniger hellen Grautönen ausgehend nach innen zurückgezogen.
Detail_dilate


Die Einstellung Detail Dilate macht das Gegenteil von Detail Erode. Hierbei werden die helleren (weißen und hellgrauen) Bereiche der Maske nach außen erweitert. Je höher der Wert, desto mehr werden die hellen Grautöne in Richtung Weiß gezogen und die Maske wirkt größer und weicher. Dadurch füllt die Maske auch feinere Details besser aus.
Black_point:


Die Einstellung black_point legt fest, ab welchem Grauwert die Maske komplett schwarz wird. Je höher der Wert, desto mehr Grautöne werden als Schwarz interpretiert. Das bedeutet, dass die dunkleren Bereiche der Maske stärker abgedunkelt werden und feine, halbdurchsichtige Kanten schneller verschwinden. Dadurch wirkt die Maske insgesamt härter.
White_point:


Die Einstellung Whitepoint legt fest, ab welchem Grauwert die Maske komplett weiß wird. Je niedriger der Wert, desto mehr Grautöne werden als Weiß interpretiert. Dadurch werden auch schwächere, halbtransparente Bereiche aufgehellt und die Maske wirkt dichter.
Process_detail
Wenn Process Detail eingeschaltet ist, werden alle kantenverbessernden Methoden aktiviert. Das angezeigte Bild zeigt die unverbesserte BiRefNet-Maske.

Device
Hier kann ausgewählt werden, ob die Maske von der Grafikkarte (GPU) oder der CPU berechnet werden soll. Die Grafikkarte (GPU) ist besser, da sie für parallele Berechnungen optimiert ist und große Datenmengen gleichzeitig verarbeiten kann – ideal für Bildverarbeitung und Maskenerstellung. Dadurch sind die Masken deutlich schneller fertig als mit der CPU.
Max_megapixel
Dieser Parameter legt die maximale Bildgröße fest, die von VITMatte verarbeitet wird. Wenn ein Bild größer als dieser Wert ist, wird es vor der Verarbeitung auf die angegebene Größe skaliert und danach wieder auf die ursprüngliche Größe zurückskaliert. Ist das Bild kleiner als der festgelegte Wert, wird es in seiner Originalgröße verarbeitet, ohne Hochskalierung.
3 Florence 2
Automatische Maskenerstellung
Florence 2 ist ein Vision-Modell, das eine Vielzahl von Vision-Language-Aufgaben ausführen kann. Auch wenn Florence 2 viel mehr kann, benutze ich es beim Masking vor allem, um eine Vorauswahl zu treffen weil es nicht so genau ist wie BiRefNet. Der besondere Vorteil von Florence 2 liegt darin, dass die Segmentierung bzw. Maskierung über einen Prompt gesteuert werden kann, wodurch einfache Maskierungsprozesse automatisiert werden.
Vorauswahl mit Florence 2 (Maske mit Zielobjekt)
↓
Crop (Bild zuschneiden)
↓
Cropped Bild
↓
Birefnet (Finale Maske erstellen)
Florence 2 Modellübersicht
Diese Übersicht zeigt die Unterschiede zwischen den Florence 2 Modellen (base und large) sowie deren finetuned (ft) Varianten. Für Maskierungsaufgaben kann die base-Variante genutzt werden, um Ressourcen zu schonen. Die Tabelle hilft dabei, die Unterschiede zu erkennen und das passende Modell für die jeweilige Aufgabe auszuwählen.
| Modell(Link) | Captions (CIDEr) | VQA (Acc) | TextVQA (Acc) | RefCOCO (Acc) | RefCOCOg (Acc) | Segmentierung (mIoU) |
|---|---|---|---|---|---|---|
| Florence-2-base | 140.0 | 79.7 | 63.6 | 92.6 | 89.8 | 78.0 |
| Florence-2-base-ft | 144.5 | 82.2 | 63.6 | 92.6 | 89.8 | 78.0 |
| Florence-2-large | 143.3 | 81.7 | 73.5 | 93.4 | 91.2 | 79.0 |
| Florence-2-large-ft | 149.1 | 84.3 | 73.5 | 93.4 | 91.2 | 79.0 |
Aufgabenbeschreibung:
- Captions: Automatische Erstellung von Bildunterschriften.
- VQA : Beantwortet Fragen zu Bildinhalten.
- TextVQA : Erkennt und verarbeitet Text in Bildern.
- RefCOCO : Lokalisiert Objekte mit kurzen, präzisen Textanweisungen.
- RefCOCOg : Lokalisiert Objekte mit längeren, detaillierten Textanweisungen.
- Segmentierung: Trennt Bildbereiche und erzeugt Masken.
Im Masking-Workflow werden zwei Node-Pakete verwendet, um Florence 2-Modelle einzubinden:
- ComfyUI-Florence2 von kijai
- ComfyUI_Layerstyle_Advance von chflame163
Masken können aber auch unabhängig von solchen Modellen realisiert werden z.B. auf Basis von Farben oder anderen Bildeigenschaften. Jede Eigenheit die dein Ziel von allem anderen unterscheidet, kann potentiell dafür genutzt werden eine Maske zu erstellen und den Prozess zu automatisieren.
ComfyUI-Florence2
Im folgenden Abschnitt werden die Parameter der Nodes Download and Load Florence 2 Model und Florence 2 Run vom Masking-Workflow erklärt. Mit ihnen kann man auf Basis eines manuell angegebenen Prompts ein Objekt automatisch maskieren lassen.
DownloadAndLoadFlorence2Model
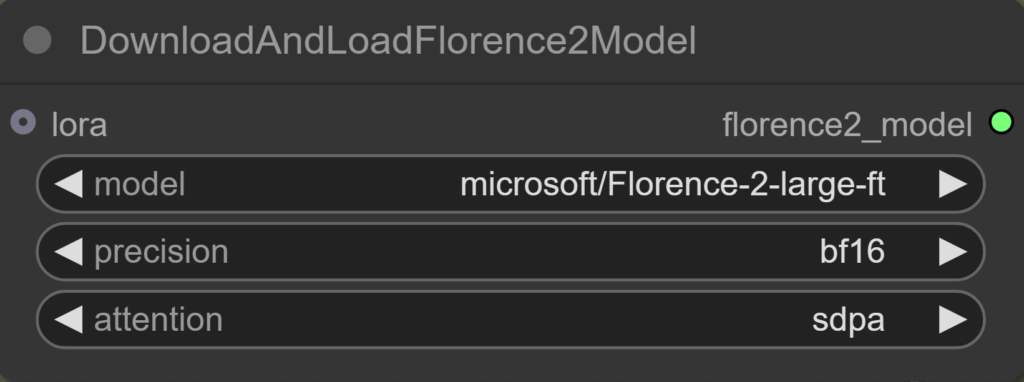
Model
Auswahl des Florence-2-Modells, das automatisch heruntergeladen wird.
Precision
Bestimmt die Genauigkeit der Berechnungen:
- fp16: Schnell und speichersparend.
- bf16: Ähnliche Genauigkeit wie fp32, aber weniger speicherintensiv (verwenden, wenn die Grafikkarte es unterstützt).
- fp32: Höchste Präzision, aber langsamer und speicherintensiv.
Attention
Legt die Methode zur Berechnung der Attention fest:
- sdpa (Scaled Dot-Product Attention): Höchste Genauigkeit und Stabilität (empfohlen).
- eager: ?
- flash_attention_2: Speicher- und Zeitaufwand bei langen Sequenzen wird reduziert, eine Art Tiling. Leichte Genauigkeitseinbußen.
Florence2Run
Mit der Florence2Run-Node kontrollierst du, welche Vision-Task ausgeführt werden soll und welche Verarbeitungsoptionen dabei verwendet werden.
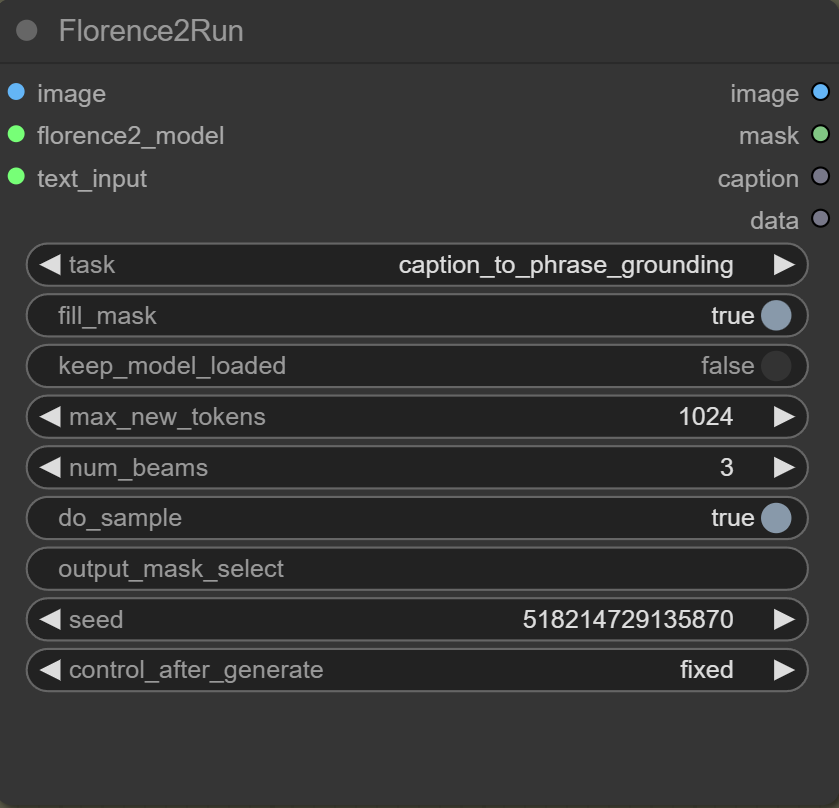
task
Der Parameter task bestimmt die Art der Aufgabe, die das Modell ausführt.
Prompt Generierung
caption: Erstellt eine kurze Beschreibung (Prompt) des gesamten Bildes.detailed_caption: Bietet eine detaillierte Beschreibung (Prompt) des Bildes.more_detailed_caption: Liefert eine noch umfassendere Bildbeschreibung (Prompt).region_caption: Erstellt Prompts für einzelne Bildregionen.dense_region_caption: Generiert Prompts für mehrere relevante Regionen gleichzeitig.
Region Proposal
region_proposal: Liefert Vorschläge für Bildregionen, die von Interesse sein könnten.
Grounding (Objektverknüpfung)
caption_to_phrase_grounding: Nutzt einen Prompt, um ein bestimmtes Objekt grob zu lokalisieren.referring_expression_segmentation: Segmentiert ein Objekt pixelgenau anhand eines Prompts.
Texterkennung (OCR)
ocr: Erkennt Text im Bildocr_with_region: Erkennt Text in bestimmten Regionen des Bildes.
Dokumentanalyse
docvqa: Beantwortet Fragen auf Basis von Dokumentbildern (Document Visual Question Answering).
Prompt Generierung und Analyse
prompt_gen_mixed_caption_plus: Erweitert die gemischte Promptbeschreibung mit weiteren Informationen.prompt_gen_tags: Generiert Tags basierend auf dem Bildinhalt.prompt_gen_mixed_caption: Kombiniert verschiedene Prompts zu einer gemischten Caption.prompt_gen_analyze: Analysiert das Bild zur Erzeugung von Beschreibungsprompts.
fill_mask
Füllt Löcher in Masken. Muss für caption_to_phrase_grounding auf true gesetzt werden, damit das Objekt korrekt lokalisiert werden kann.
keep_model_loaded
Aktivieren, um die Bearbeitung zu beschleunigen. Das Modell ist so schneller verfügbar.
max_new_tokens
Legt die maximale Anzahl an generierbaren Tokens fest. Tokenwerte unter 1024 können zu abgeschnittenen Masken führen. Bei caption_to_phrase_grounding hat es ab 9 Tokens funktioniert, aber es empfiehlt sich, den Standardwert von 1024 beizubehalten, um die Maskenqualität zu gewährleisten.
num_beams
Bestimmt die Anzahl der Suchpfade im Beam-Search-Algorithmus, der bei der Textgenerierung verwendet wird. Ein höherer Wert kann die Qualität des generierten Textes verbessern, erhöht jedoch den Rechenaufwand.
do_sample
Der Parameter do_sample beeinflusst die Textgenerierung. Auf true werden die Texte kreativer und abwechslungsreicher.
output_mask_select
Ermöglicht es, bei mehreren erkannten Segmenten in einem Bild ein bestimmtes Segment auszuwählen.
Seed
Legt den Startpunkt für Modelle wie Florence 2 fest. Durch Festlegen eines bestimmten Seed-Wertes kann das Modell bei wiederholten Läufen mit demselben Seed und identischen Eingaben konsistente Ausgaben erzeugen.
control_after_generate
Ändert den Seed nach jeder Generierung – außer bei fixed, da bleibt er gleich. Andere Optionen sind random, increment und decrement, um verschiedene Ergebnisse zu erzeugen.
ComfyUI_Layerstyle_Advance
Will man sogar den Prompt automatisch erstellen lassen und so die Chance darauf haben, dass der Prozess vollautomatisch funktioniert, kann man die Nodes „Load Florence2 Model“ und „Florence2 Image2Prompt“ nutzen. Achte darauf, dass die Tasks von „Florence2Run“ und „Florence2 Image2Prompt“ zueinander passen. Description hat in meinem Fall am besten funktioniert.
Load Florence2 Model
Sehr einfach zu benutzen. Die Modelle können hier ausgewählt werden und werden anschließend automatisch heruntergeladen. Achte darauf, dass das Modell zum ausgewählten Task passt.
Florence2 Image2Prompt
Einige Tasks bei der Node überschneiden sich mit den Tasks von „Florence2Run“. Im Folgenden werden die zusätzlichen, neuen Tasks erklärt:
description:
- Erstellt eine allgemeine Beschreibung des Bildes, ähnlich wie „detailed_caption“.
object detection:
- Erkennt und lokalisiert verschiedene Objekte im Bild und benennt diese.
region proposal (mask):
- Vorschläge für relevante Bildregionen und erstellt gleichzeitig Masken für diese Regionen.
open vocabulary detection:
- Erkennt und lokalisiert Objekte im Bild, ohne auf vordefinierte Kategorien festgelegt zu sein. Die Kategorien sind offen und flexibel.
region to category:
- Ordnet erkannten Regionen im Bild passende Kategorien zu und klassifiziert diese entsprechend.
region to description:
- Erstellt spezifische textliche Beschreibungen für die ausgewählten Bildregionen, anstatt das gesamte Bild zu beschreiben.
Ich hoffe, der Artikel war hilfreich für dich 🙂


