Übersicht
1 Grundlagen
In diesem Artikel geht es darum wie man in ComfyUI genau und komfortabel Bilder zuschneidet und um ein grundlegendes Verständnis von Cropping.
Alle Methoden die ich hier vorstelle sind in meinem Cropping-Workflow, den du hier herunterladen kannst, enthalten.
ComfyUI ist aktuell(Anfang 2025) nicht das beste Werkzeug um Bildausschnitte zu erzeugen, Programme wie Photoshop bieten die besten Benutzeroberflächen und Funktionen, wenn du Photoshop hast und es in deinen Workflow einbauen möchtest, gehe zu Punkt 6 des Artikels. Dort gebe ich eine Übersicht.
Warum Cropping?
Will man nur mit einem bestimmten Bereich eines Bildes arbeiten , nutzt man Cropping Nodes, um diesen vom Rest zu trennen indem alles außerhalb einer Auswahl permanent entfernt wird.
Grundsätzlich ist das Ergebnis eines Zuschnittes immer ein Bild im viereckigen Format, selbst wenn der sichtbare Ausschnitt kein Viereck ist.


Die Seitenlängen des Bildes entsprechen also dem umgebenden Viereck, das die Auswahl einschließt. Das liegt daran, dass digitale Bilder auf einem viereckigen Pixelraster basieren und entweder alle Pixel sichtbar sind oder zum Teil transparent dargestellt werden. Das ist wichtig zu beachten, denn die Seitenlängen des Ausschnittes sollten in einer Auflösung sein oder zu einer Auflösung führen können, mit denen die entsprechenden KI Modelle wie SD1.5, SDXL oder Flux die besten Ergebnisse liefern wenn man weiter mit dem Bild arbeiten will.
Die Herausforderung in ComfyUI besteht darin, die Dimensionen (Seitenlängen) und Position (X- und Y-Koordinaten) des Ausschnittes sowie die Orientierung (Drehwinkel θ) des Bildes so genau und komfortabel wie möglich einstellen zu können.
Es gibt zwei gängige Wege, um Dimension und Position des Bildausschnittes in ComfyUI zu bestimmen:
Cropping mit Mask Editor
Markieren des gewünschten Bereich im Mask Editor – die Maske wird an die CropByMask V2 Node übergeben und bestimmt, wie das Bild zugeschnitten wird.
- Vorteil: Schnelle und intuitive Auswahl.
- Nachteil: Keine Kontrolle über die genauen Parameter
Exakte Angaben der Werte
- Vorteil: Präzise Kontrolle der Parameter.
- Nachteil: Umständliche Positionierung, da man nicht direkt auf dem Bild arbeitet.
Beide Methoden werden von mir vorgestellt, aber ich bin der Ansicht, dass die Wahl des Ausschnittes mit dem Mask Editor oft die bessere Option ist. Da viele Anforderungen, wie z.B. die Teilbarkeit der Seitenlängen durch 8,16,32… im Nachhinein anpasst werden können.
2 Cropping mit Mask Editor
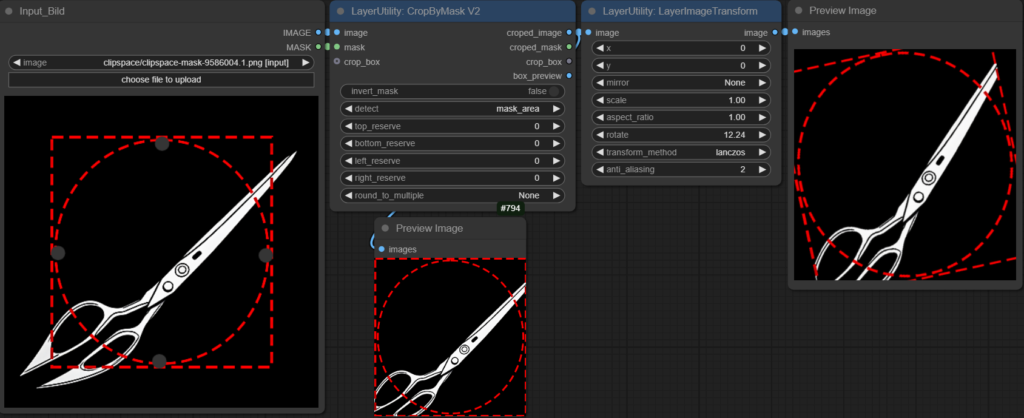
Bei unterschiedlichen Bildern ist das setzen des Ausschnittes über den Mask Editor praktisch, weil man intuitiv die Grenzen bestimmen kann. Für den eigentlichen Ausschnitt nutze ich die CropByMask V2 Node von ComfyUI_LayerStyle. Sie gibt einem die Möglichkeit die Position und Dimension des Ausschnittes mit einer Maske oder direkt über eine crop_box zu bestimmen.
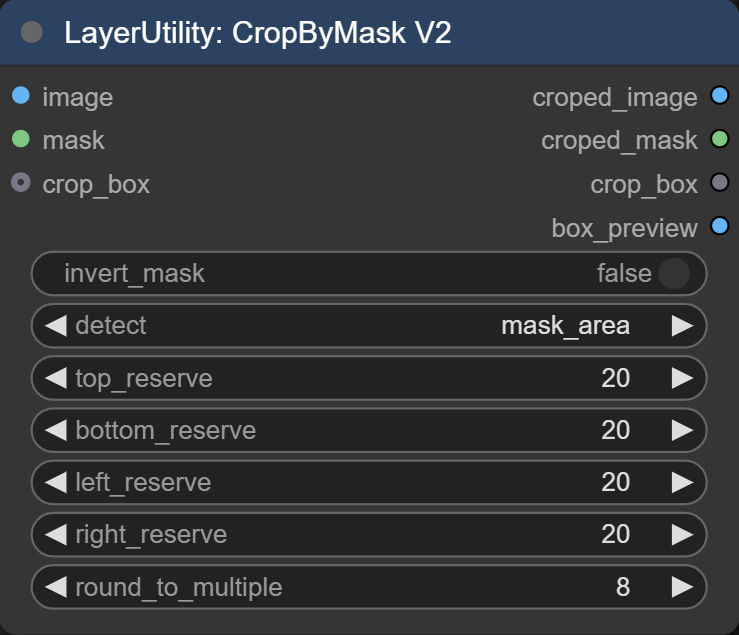
Input:
- Die Maske, die aus dem Mask-Editor stammt, bestimmt die Position und Maße der Auswahl.
- Eine crop_box ist die Angabe der Seitenlängen, sowie die genaue Position des auszuschneidenden Vierecks. Wenn man diese Informationen aus vorherigen Arbeitsschritten hat kann man sie direkt einbinden und damit die Maskenoption überschreiben.
Einstellungen
- invert_mask: Umkehren der Maske. Schwarz wird Weiß, Weiß wird Schwarz.
- detect: Wie soll zugeschnitten werden. Es gibt 3 Optionen:
- detect(mask_area): Technisch gesehen schaut die Node nach dem äußersten linken, rechten, oberen und unteren Pixel der Maske. Daraus ergibt sich das „begrenzende“ Viereck, das die Auswahl umschließt.

- detect(min_bounding_rect): Umschließt die größte zusammenhängende Maskenfläche mit einem Viereck.
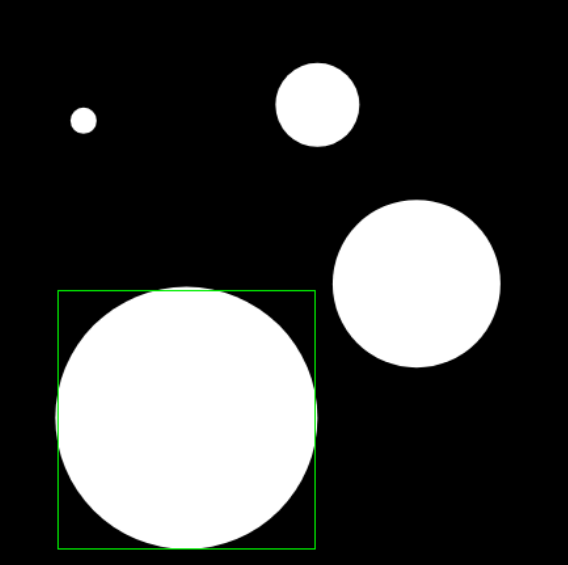
- detect(?max_inscribed_rect?): Theoretisch wird ein Viereck, das vollständig innerhalb der größten weißen Maskenfläche liegt erzeugt.
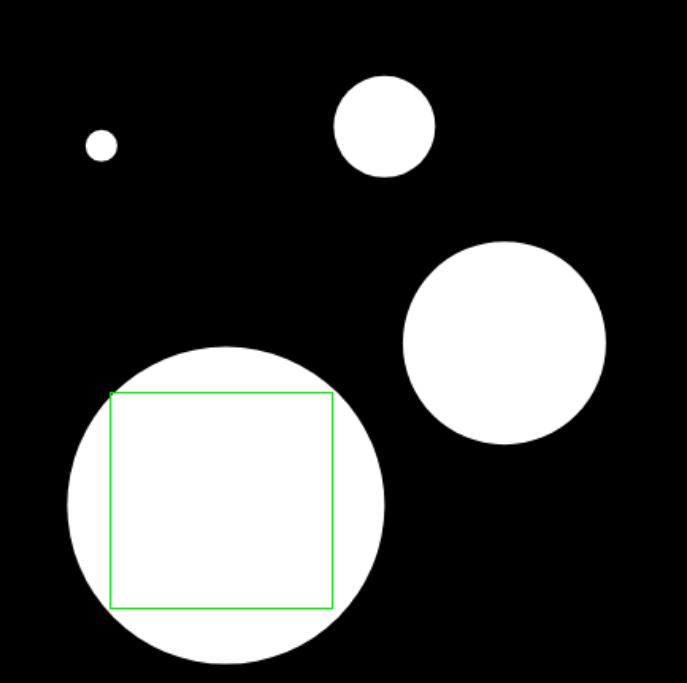
Allerdings gilt das nur ab einer gewissen Größe von etwa 50×50 Pixeln Maskenfläche. Je nach Form liegt das Viereck außerhalb der Maskenfläche und wenn zwei Flächen zu nahe aneinander sind werden sie als eine erkannt.
- reserve: Erweitert oder mindert den Ausschnitt um eine feste Anzahl von Pixeln.
- round_to_multiple: Seitenlängen des Ausschnittes werden zu einem Mehrfachen von 8, 16, 32, 64, 128, 256 oder 512. Wählt man z.B. 8, ermittelt die Node, welches Vielfache von 8 der Bildbreite und -höhe der Auswahl am nächsten kommt, und passt die Seitenlängen entsprechend an.
Output:
- Croped Image: Bildausschnitt
- croped_mask: Maskenausschnitt
- crop_box: Position und Dimension des Ausschnitts in einem Parameter.
- box_preview: Vorschau des Bildausschnittes. Rot stellt die erkannte Fläche da und Grün den Ausschnitt mit reserve. Im Beispiel ist die reserve auf 0 eingestellt.

Meistens nutze ich mask_area ohne reserve und round_to_multiple of 8, um möglichst genau die Maske auszuschneiden, die ich erstellt habe, aber trotzdem eine Seitenlänge zu haben, mit der die Modelle besser umgehen können
3 Cropping mit automatischer Maske
Um Masken erstellen zu lassen, gibt es die Möglichkeit, Computer-Vision-Modelle zu nutzen. Das sind Modelle, die in einem Bild genau die Bereiche erkennen, die uns wichtig sind, und diese markieren.
Florence2 ist ein solches Vision-Modell, das eine Vielzahl von Vision-Language-Aufgaben ausführen kann. Während es für viele Aufgaben eingesetzt werden kann, nutzen wir es hier um eine Maske erstellen zu lassen und anschließend das Bild zu croppen. Der besondere Vorteil von Florence 2 liegt darin, dass die Segmentierung bzw. Maskierung über einen Prompt gesteuert werden kann, wodurch einfache Maskierungsprozesse automatisiert werden.
Vorauswahl mit Florence 2 (Maske mit Zielobjekt)
↓
Crop (Bild zuschneiden)
↓
Cropped Bild
Florence 2 Modellübersicht
Diese Übersicht zeigt die Unterschiede zwischen den Florence 2 Modellen (base und large) sowie deren finetuned (ft) Varianten. Für Maskierungsaufgaben kann die base-Variante genutzt werden, um Ressourcen zu schonen. Die Tabelle hilft dabei, die Unterschiede zu erkennen und das passende Modell für die jeweilige Aufgabe auszuwählen.
| Modell(Link) | Captions (CIDEr) | VQA (Acc) | TextVQA (Acc) | RefCOCO (Acc) | RefCOCOg (Acc) | Segmentierung (mIoU) |
|---|---|---|---|---|---|---|
| Florence-2-base | 140.0 | 79.7 | 63.6 | 92.6 | 89.8 | 78.0 |
| Florence-2-base-ft | 144.5 | 82.2 | 63.6 | 92.6 | 89.8 | 78.0 |
| Florence-2-large | 143.3 | 81.7 | 73.5 | 93.4 | 91.2 | 79.0 |
| Florence-2-large-ft | 149.1 | 84.3 | 73.5 | 93.4 | 91.2 | 79.0 |
Aufgabenbeschreibung:
- Captions: Automatische Erstellung von Bildunterschriften.
- VQA : Beantwortet Fragen zu Bildinhalten.
- TextVQA : Erkennt und verarbeitet Text in Bildern.
- RefCOCO : Lokalisiert Objekte mit kurzen, präzisen Textanweisungen.
- RefCOCOg : Lokalisiert Objekte mit längeren, detaillierten Textanweisungen.
- Segmentierung: Trennt Bildbereiche und erzeugt Masken.
Im Cropping-Workflow werden zwei Node-Pakete verwendet, um Florence 2-Modelle einzubinden:
- ComfyUI-Florence2 von kijai
- ComfyUI_Layerstyle_Advance von chflame163
ComfyUI-Florence2
Im folgenden Abschnitt werden die Parameter der Nodes Download and Load Florence 2 Model und Florence 2 Run vom Cropping-Workflow erklärt. Mit ihnen kann man auf Basis eines manuell angegebenen Prompts ein Objekt automatisch maskieren lassen.
DownloadAndLoadFlorence2Model
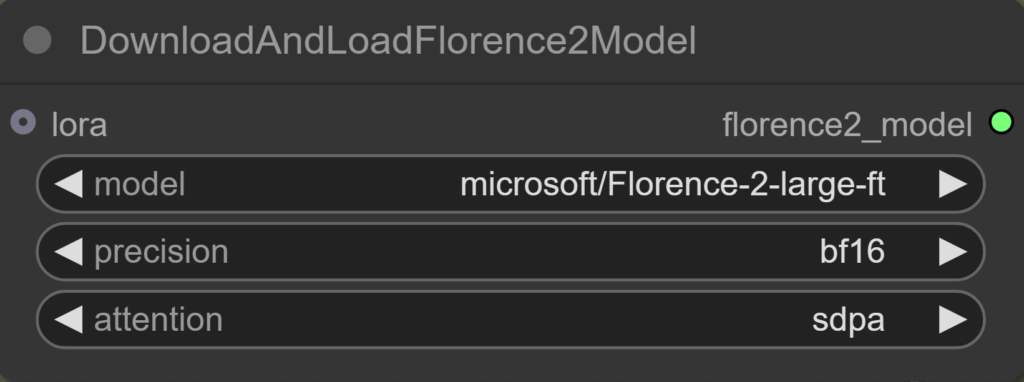
Model
Auswahl des Florence-2-Modells, das automatisch heruntergeladen wird.
Precision
Bestimmt die Genauigkeit der Berechnungen:
- fp16: Schnell und speichersparend.
- bf16: Ähnliche Genauigkeit wie fp32, aber weniger speicherintensiv (verwenden, wenn die Grafikkarte es unterstützt).
- fp32: Höchste Präzision, aber langsamer und speicherintensiv.
Attention
Legt die Methode zur Berechnung der Attention fest:
- sdpa (Scaled Dot-Product Attention): Höchste Genauigkeit und Stabilität (empfohlen).
- eager: ?
- flash_attention_2: Speicher- und Zeitaufwand bei langen Sequenzen wird reduziert, eine Art Tiling. Leichte Genauigkeitseinbußen.
Florence2Run
Mit der Florence2Run-Node kontrollierst du, welche Vision-Task ausgeführt werden soll und welche Verarbeitungsoptionen dabei verwendet werden.
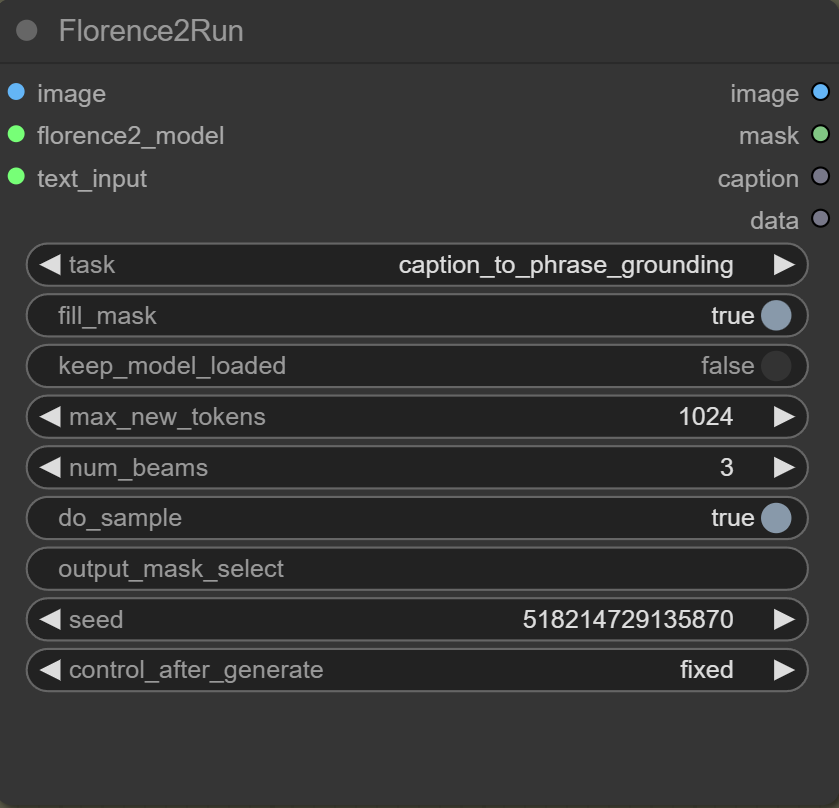
task
Der Parameter task bestimmt die Art der Aufgabe, die das Modell ausführt.
Prompt Generierung
caption: Erstellt eine kurze Beschreibung (Prompt) des gesamten Bildes.detailed_caption: Bietet eine detaillierte Beschreibung (Prompt) des Bildes.more_detailed_caption: Liefert eine noch umfassendere Bildbeschreibung (Prompt).region_caption: Erstellt Prompts für einzelne Bildregionen.dense_region_caption: Generiert Prompts für mehrere relevante Regionen gleichzeitig.
Region Proposal
region_proposal: Liefert Vorschläge für Bildregionen, die von Interesse sein könnten.
Grounding (Objektverknüpfung)
caption_to_phrase_grounding: Nutzt einen Prompt, um ein bestimmtes Objekt grob zu lokalisieren.referring_expression_segmentation: Segmentiert ein Objekt pixelgenau anhand eines Prompts.
Texterkennung (OCR)
ocr: Erkennt Text im Bildocr_with_region: Erkennt Text in bestimmten Regionen des Bildes.
Dokumentanalyse
docvqa: Beantwortet Fragen auf Basis von Dokumentbildern (Document Visual Question Answering).
Prompt Generierung und Analyse
prompt_gen_mixed_caption_plus: Erweitert die gemischte Promptbeschreibung mit weiteren Informationen.prompt_gen_tags: Generiert Tags basierend auf dem Bildinhalt.prompt_gen_mixed_caption: Kombiniert verschiedene Prompts zu einer gemischten Caption.prompt_gen_analyze: Analysiert das Bild zur Erzeugung von Beschreibungsprompts.
fill_mask
Füllt Löcher in Masken. Muss für caption_to_phrase_grounding auf true gesetzt werden, damit das Objekt korrekt lokalisiert werden kann.
keep_model_loaded
Aktivieren, um die Bearbeitung zu beschleunigen. Das Modell ist so schneller verfügbar.
max_new_tokens
Legt die maximale Anzahl an generierbaren Tokens fest. Tokenwerte unter 1024 können zu abgeschnittenen Masken führen. Bei caption_to_phrase_grounding hat es ab 9 Tokens funktioniert, aber es empfiehlt sich, den Standardwert von 1024 beizubehalten, um die Maskenqualität zu gewährleisten.
num_beams
Bestimmt die Anzahl der Suchpfade im Beam-Search-Algorithmus, der bei der Textgenerierung verwendet wird. Ein höherer Wert kann die Qualität des generierten Textes verbessern, erhöht jedoch den Rechenaufwand.
do_sample
Der Parameter do_sample beeinflusst die Textgenerierung. Auf true werden die Texte kreativer und abwechslungsreicher.
output_mask_select
Ermöglicht es, bei mehreren erkannten Segmenten in einem Bild ein bestimmtes Segment auszuwählen.
Seed
Legt den Startpunkt für Modelle wie Florence 2 fest. Durch Festlegen eines bestimmten Seed-Wertes kann das Modell bei wiederholten Läufen mit demselben Seed und identischen Eingaben konsistente Ausgaben erzeugen.
control_after_generate
Ändert den Seed nach jeder Generierung – außer bei fixed, da bleibt er gleich. Andere Optionen sind random, increment und decrement, um verschiedene Ergebnisse zu erzeugen.
ComfyUI_Layerstyle_Advance
Will man sogar den Prompt automatisch erstellen lassen und so die Chance darauf haben, dass der Prozess vollautomatisch funktioniert, kann man die Nodes „Load Florence2 Model“ und „Florence2 Image2Prompt“ nutzen. Achte darauf, dass die Tasks von „Florence2Run“ und „Florence2 Image2Prompt“ zueinander passen. Description hat in meinem Fall am besten funktioniert.
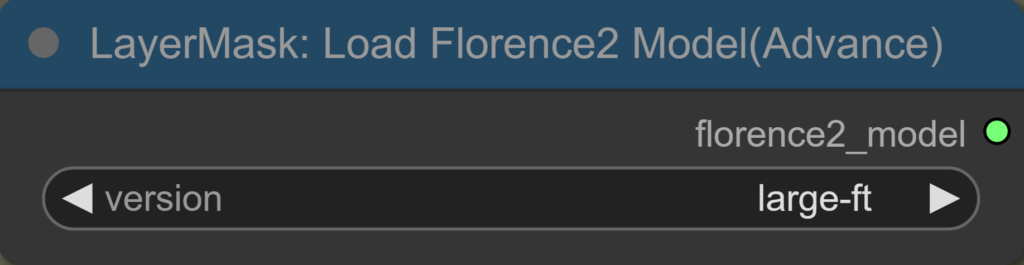
Load Florence2 Model
Sehr einfach zu benutzen. Die Modelle können hier ausgewählt werden und werden anschließend automatisch heruntergeladen. Achte darauf, dass das Modell zum ausgewählten Task passt.
Florence2 Image2Prompt
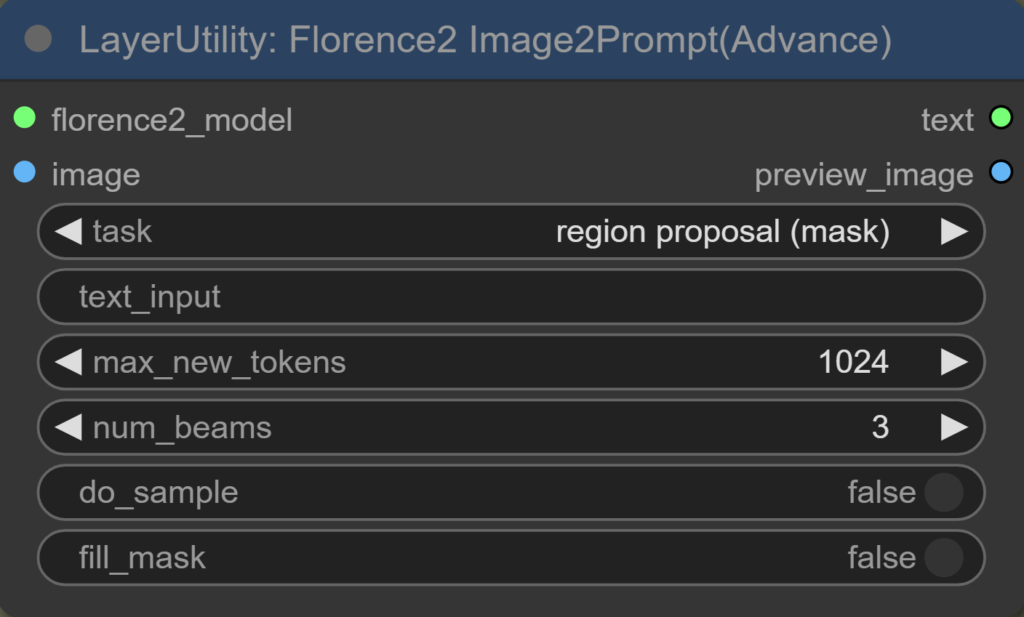
Einige Tasks bei der Node überschneiden sich mit den Tasks von „Florence2Run“. Im Folgenden werden die zusätzlichen, neuen Tasks erklärt:
description:
- Erstellt eine allgemeine Beschreibung des Bildes, ähnlich wie „detailed_caption“.
object detection:
- Erkennt und lokalisiert verschiedene Objekte im Bild und benennt diese.
region proposal (mask):
- Vorschläge für relevante Bildregionen und erstellt gleichzeitig Masken für diese Regionen.
open vocabulary detection:
- Erkennt und lokalisiert Objekte im Bild, ohne auf vordefinierte Kategorien festgelegt zu sein. Die Kategorien sind offen und flexibel.
region to category:
- Ordnet erkannten Regionen im Bild passende Kategorien zu und klassifiziert diese entsprechend.
region to description:
Hilfreiche YouTube Videos zum Thema Florence-2 findest du Hier:
- Instalation von ComfyUI-Florence2 : https://www.youtube.com/watch?v=Jw3AX92fzi8
- Florence-2-large-ft Model Download ab Minute 2:34: https://www.youtube.com/watch?v=MPv27j9qn50&t=397s
Masken können aber auch unabhängig von solchen Modellen realisiert werden z.B. auf Basis von Farben oder anderen Bildeigenschaften. Jede Eigenheit die dein Ziel von allem anderen unterscheidet, kann potentiell dafür genutzt werden eine Maske zu erstellen und den Prozess zu automatisieren.
4 Exakte Angaben
Ein Bild kann direkt über die Angaben der Seitenlängen und Position zugeschnitten werden. Das ist am sinnvollsten wenn die Daten bereits vorhanden sind. Node Pakete wie was-node-suite-comfyui oder ComfyUI_essentials bieten dafür Nodes. Typisch ist das wie im folgenden Bild zu sehen, der Nullpunkt des Koordinatensystems oben links im Bild ist und das die Cropdaten als Output verfügbar sind.
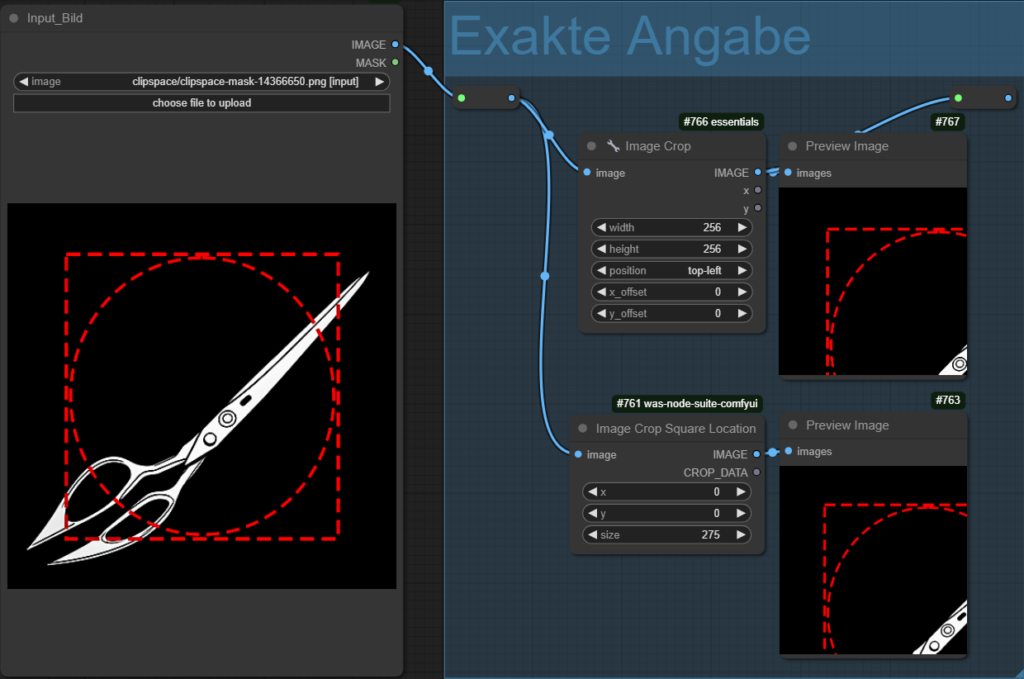
5 Drehwinkel/Orientierung
Arbeitet man mit der CropByMask V2 Node, ist es egal welche Orientierung die Maske hat, welche man der Cropping Node gibt. Die Node interessiert nur, wo die äußeren Grenzen der Maske sind und erstellt so die viereckige crop_box. Der Effekt einer Drehung ist, dass die crop_box größer wird aber nicht das sich der Ausschnitt dreht.
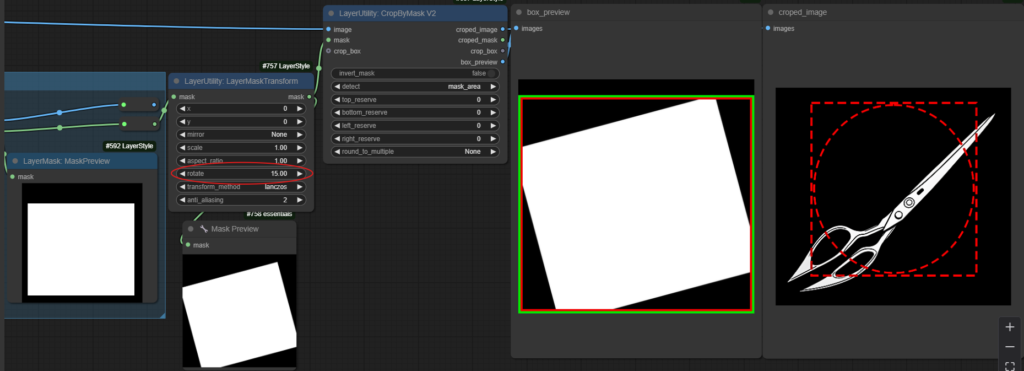
Will man die Orientierung des Bildausschnittes ändern, gibt die Node Layer Image Transform von ComfyUI_LayerStyle die Möglichkeit den Inhalt des Ausschnittes zu drehen.
Man dreht nur das Bildmotiv, das sich innerhalb des festgelegten Vierecks befindet. Man kann sich das vorstellen, als würde man in einem Bilderrahmen das Foto im Inneren drehen, ohne den Rahmen selbst zu bewegen.
Folgen:
- Ein Teil des ursprünglichen Bildinhaltes geht verloren, weil das Bild durch die Drehung teilweise „aus dem Rahmen“ herausfällt. Im obigen Bild verschwinden die Ecken.
- An Stellen, wo nach der Drehung „nichts“ wäre, werden die Pixel Schwarz.
- Die äußeren Kanten des Ausschnittes (der Rahmen selbst) bleiben in ihrer Größe (Breite × Höhe) gleich. Du änderst nur, was darin zu sehen ist, nicht das Format des Ausschnitts.
Image Transform Node:
Input:
- Bild
Einstellungen:
- x= Verschieben des Bildes auf x-Achse
- y=Verschieben des Bildes auf y-Achse
- mirror flipping=Horizontales oder vertikales spiegeln des Bildes
- scale= Ansicht ändern. Werte über 1,0 vergrößern (zoomen heran) und Werte unter 1,0 verkleinern (zoomen heraus). Die Seitenlängen bleiben gleich.
- aspect ratio= Seitenverhältnis des Bildes. Werte größer als 1.0 bedeuten eine Streckung und Werte kleiner als 1.0 bedeuten eine Stauchung
- rotate: Das Bild wird um sein Zentrum gedreht, ohne es zu vergrößern. Wenn du einen viereckigen Ausschnitt nicht genau auf 0, 90, 180, 270 oder 360 Grad einstellst, liegen manche Stellen außerhalb des ursprünglichen Rahmens und werden nicht angezeigt.
- transform_methods: Wird das Bild in diesem Schritt vergrößert/gedreht, kann man hier die Methode festlegen, mit der die Vergrößerung/Drehung berechnet wird. Lanczos führt in der Regel zu den besten Ergebnissen.
- anti_aliasing: Je höher die Zahl, desto glatter werden die Übergänge und Kanten
Output:
- Rotiertes Bild
Am Anfang habe ich nicht verstanden, dass Lanczos ein Algorithmus zur Bildskalierung und -rotation ist. Da ich nicht wusste, dass beim Rotieren eines Bildes die Pixel neu angeordnet werden. Der Grund ist, dass das Bild aus einem Raster fester Pixel besteht und dieses Raster in der Regel nicht exakt zu den neuen, gedrehten Positionen passt. Durch die Drehung entstehen Zwischenräume, die nicht direkt mit vorhandenen Pixeln gefüllt werden können und neu berechnet werden müssen. Durch das Drehen können an den Kanten sogenannte Treppeneffekte (Aliasing) entstehen, die durch den anti-aliasing-Parameter gemindert werden können.
6 ComfyUI und Photoshop
Einfache Ausschnitte können in ComfyUI relativ komfortabel oder sogar automatisch gemacht werden. Die Herausforderung liegt nicht am Crop selbst, sondern daran an die Daten für den Zuschnitt zu kommen. Will man höhere Präzision und bedienerfreundliche Werkzeuge, ist es möglich Photoshop in seinen Workflow mit einzubinden. Das bedeutet, dass du eine Stelle in deinem Workflow bestimmst, an der das Bild automatisch an Photoshop geschickt wird und dort weiterbearbeitet werden kann. Im Anschluss wird es wieder zu ComfyUI geschickt und kann dort im Workflow genutzt werden.
Das ist möglich durch das Projekt comfyui-photoshop von NimaNzrii, welches seinen eigenen Artikel wert ist. Guck dir am besten seine Videos auf YouTube an, sein Kanal heißt AI with Nima, er macht gute Tutorials zur Installation der Node.


